Traditional ML engineering was very hard. It is still very hard. One of the more difficult challenges in the traditional ML lifecyle, I think, is data preparation. After joins and converting columns no one understood to floats and normalization and missing value imputation and upsampling, the lucky few who manage to train a model with good accuracy—by hook or by crook—then become responsible for monitoring a hodgepodge of ML pipeline components. (Maybe they give up to pursue a less-hectic career in software engineering.1 I was one of these people, before I started my PhD.)
Today, AI applications are faster than ever to prototype, and many more people are able to build AI applications. One can argue that LLMs have offered a (somewhat deceptive) opportunity to simplify data preparation—by circumventing it entirely. To create some pipeline around an LLM, people don’t need to write preprocessing or feature engineering code, or collect labeled training data anymore. One can simply throw some words into a prompt and return a coherent response via an API call.
Consider one reason for why data preparation for traditional ML was so challenging from an HCI or UX lens: people would need to put in so much effort to get even some shitty accuracy metric, and there were no good “progress” indicators throughout the entire workflow until some trained model emerged with better-than-average accuracy. Such effort correlates with sunk cost fallacy, particularly in organizations where leadership does not understand the finnicky nature of ML. (Not to mention how every university or AI course sells its potential like snake oil—making it feel all-the-more important to get some model deployed.) Upon deployment, people generally have such high hopes for ML, and these hopes are only deflated with time.
With LLMs, in contrast to traditional ML, the initial stages of experimentation are much lower-stakes. Because you’ve put in such little effort into data preparation,2, it’s very easy to get pleasantly surprised by initial results (which happens to be, simply, probing the LLM with a few examples and a basic prompt). This excitement propels the next stage of experimentation, also known as prompt engineering3—maybe scaling up to more inputs, observing the first few failure modes, but quickly patching them up by employing the next one-sentence prompt addition to fix the most imminent problem.
While people ship initial deployments of LLM-based pipelines much faster than traditional ML pipelines, expectations become similarly tempered once they are in production. In traditional ML, once people established confidence in the validation set accuracy, they expected something similar post-deployment (unless they were a true ML engineering expert). Generative AI and LLMs are a little more interesting in that most people don’t have any form of systematic evaluation before they ship (why would they be forced to, if they didn’t collect a training dataset?), so their expectations are set purely based on vibes.4
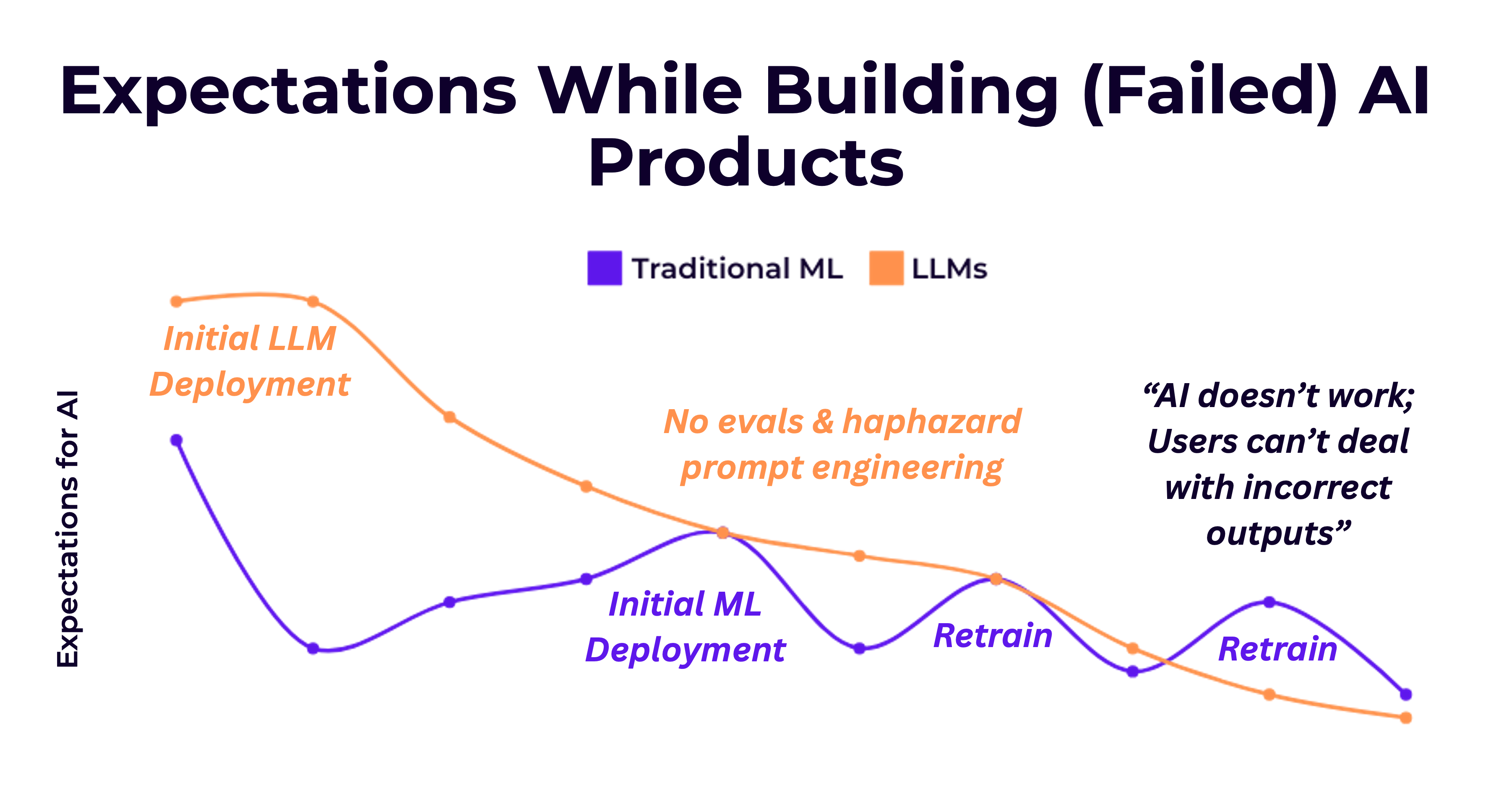
I think, in ML and AI engineering, that teams often expect too high of accuracy or alignment with their expectations from an AI application right after it’s launched, and often don’t build out the infrastructure to continually inspect data, incorporate new tests, and improve the end-to-end system. Then, over time, they only get more and more disappointed. If teams don’t start with more realistic expectations—meaning, they don’t plan for bad initial outputs and don’t invest in workflows to continually improve the application based on new data and failure modes observed—the application is likely to disappoint and fail.
When we studied the traditional MLOps lifecycle, we found one common pattern across all successful ML products—their commitment to a process of constantly-evolving data preparation, experimentation, re-training and re-deployment, and continual monitoring and debugging.5 This contrasts pretty sharply with software engineering, where outcomes after deployment are generally more predictable and improvements can be systematically planned and executed based on well-defined software characteristics. AI engineering has to mirror successful paradigms of iteration in traditional ML engineering—otherwise we are doomed, as a community, to repeat the same AI-in-production mistakes that we’ve made in the past.6
I imagine Gartner is observing the landscape of AI-powered products, eagerly waiting to document the substantial number of generative AI projects that don’t “make it to production.” I hope that reality proves more optimistic than my cynical expectations, ultimately reflecting a more successful—and widespread—integration of AI in practical applications.
Footnotes
-
MLOps platform, some people called this shift. We have data scientists to train models and no one to create infrastructure for them, people pontificated as they took millions of dollars from venture capitalists, beelining to safer places where no one blamed them for bad model performance. ↩
-
In so many LLM pipelines, especially with RAG, people copy documents and formatting verbatim into prompts. ↩
-
I love watching prompts evolve. Rarely do people intend for a prompt to become an essay; they can start small and end up becoming a messy pile of “do” and “don’t” instructions. And then, because LLMs can’t reliably follow so many instructions in every output, people may employ another LLM call to check that all the instructions were followed. “Turtles all the way down” is a common theme in AI engineering, I feel. ↩
-
While a good number of people create at least some “unit tests” or evals prior to deployment, and set their post-deployment accuracy expectations to what they observe offline, most people find it hard to do this. An immediately-relevant and impactful research problem here is how to help people boostrap data for LLM pipeline unit tests, given that they often don’t have data when turning to an LLM, without blindly querying an LLM for synthetic data that isn’t at least verified by the developer, let alone representative of the inputs observed in production. There are both interesting data preparation and HCI challenges here: for example, I have some recent work on automatically synthesizing constraints and implementations of such constraints for LLM outputs—and interesting findings that, from an HCI perspective, humans exhibit criteria drift: i.e., asking humans to evaluate open-ended generative outputs (where there are infinitely many good outputs because the definition of a “good” output is merely the absence of constraint violations) is quite difficult because human preferences change as they observe more LLM outputs. I am curious to read about more work on the alignment of algorithmic techniques (e.g., prediction-powered inference) with practical, real-world criteria drift problems. ↩
-
Much of the basis for my takes on AI engineering comes from this paper I wrote. ↩
-
Check out this practical guide to building LLM applications that I co-authored, which contains many tips on how to focus on data preparation, evaluation and monitoring processes. ↩